Pipeline of Ag2Manip
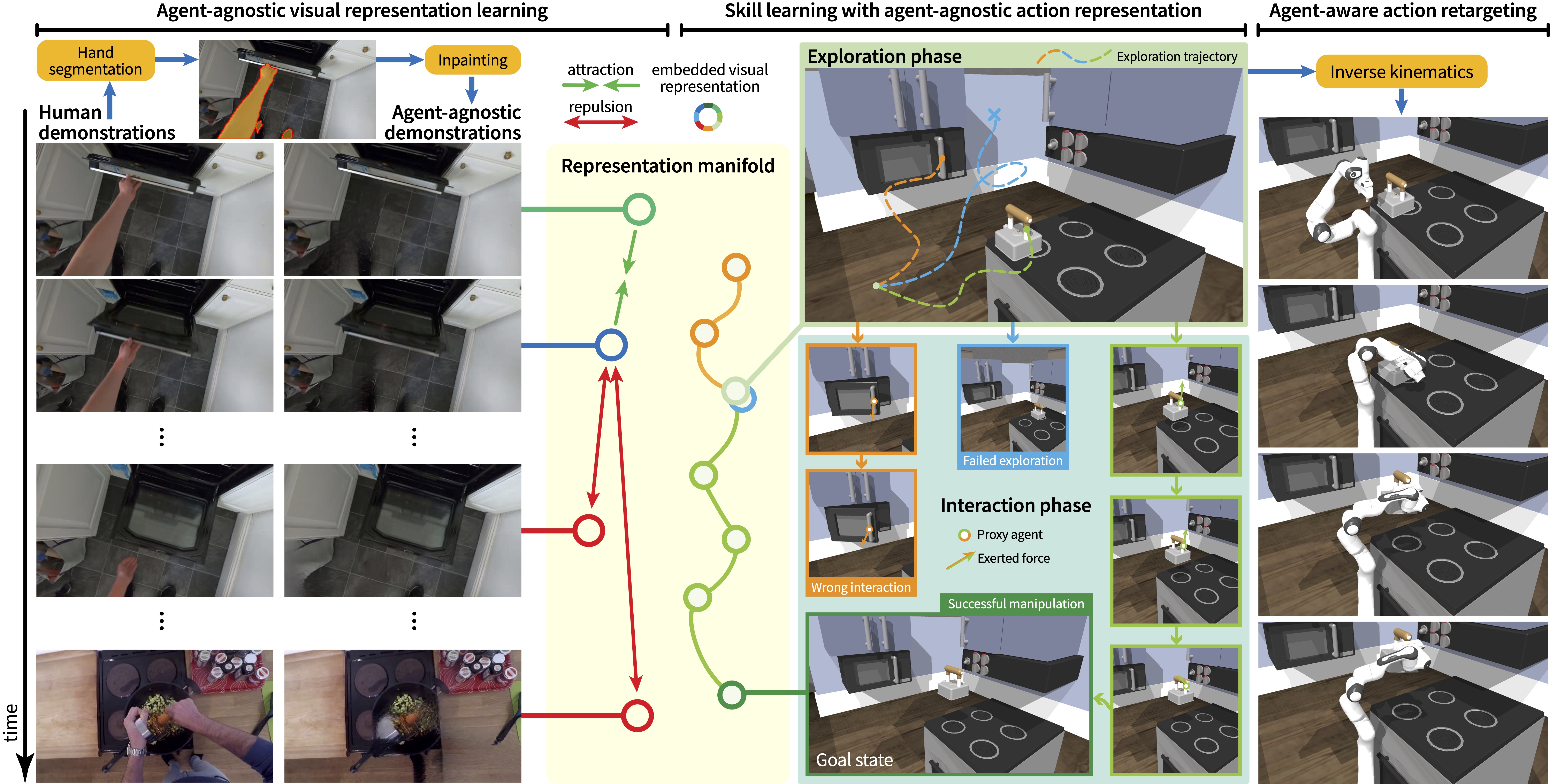
Our method consists of three parts: (left) learning an agent-agnostic visual representation; (middle) learning abstracted skills with an agent-agnostic action representation; and (right) retargeting the abstracted skills to a robot.